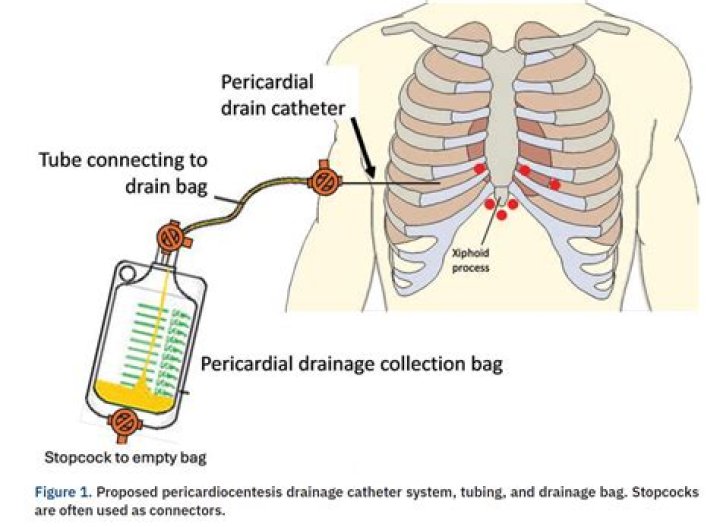
What are the classification algorithms in machine learning?
By Rachel Hickman •
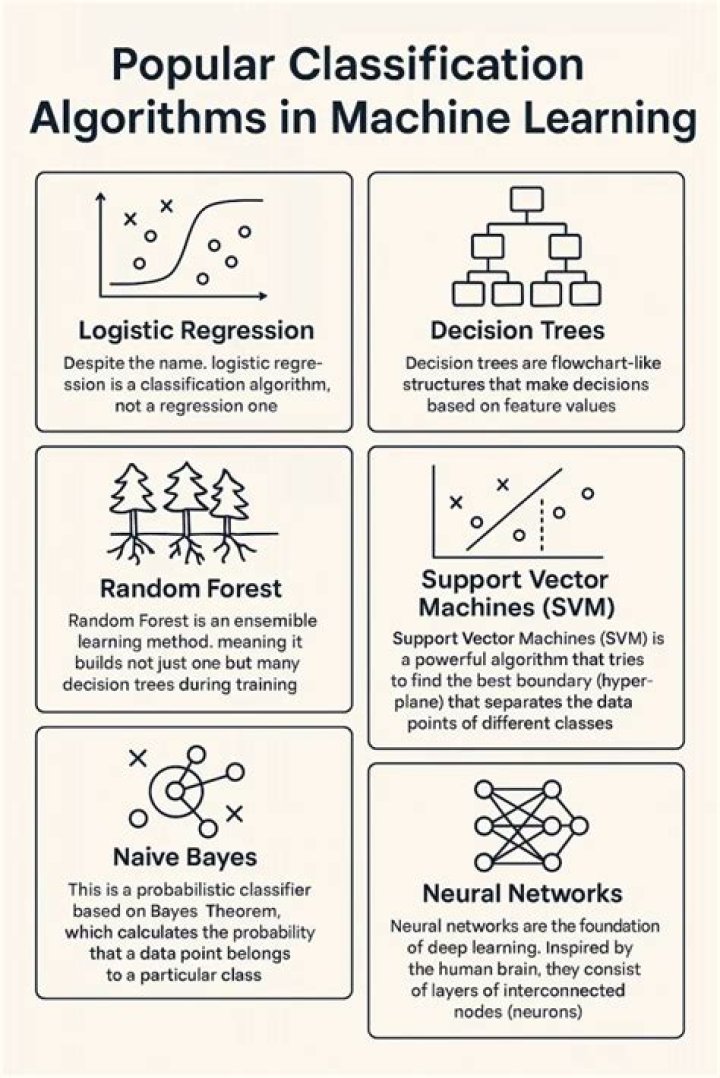
Here we have the types of classification algorithms in Machine Learning:
- Linear Classifiers: Logistic Regression, Naive Bayes Classifier.
- Nearest Neighbor.
- Support Vector Machines.
- Decision Trees.
- Boosted Trees.
- Random Forest.
- Neural Networks.
.
Consequently, what is classification algorithm?
A classification algorithm, in general, is a function that weighs the input features so that the output separates one class into positive values and the other into negative values.
Subsequently, question is, what are classes in machine learning? A class denotes a set of items (or data-points if we have to represent them in a vector-space) that have certain common characteristics (or exhibit very similar feature patterns in the ML parlance so as to imply a very specific and common interpretation.
Accordingly, how do you know which classification algorithm to use?
- 1-Categorize the problem.
- 2-Understand Your Data.
- Analyze the Data.
- Process the data.
- Transform the data.
- 3-Find the available algorithms.
- 4-Implement machine learning algorithms.
- 5-Optimize hyperparameters.
What are different types of algorithms?
Well there are many types of algorithm but the most fundamental types of algorithm are:
- Recursive algorithms.
- Dynamic programming algorithm.
- Backtracking algorithm.
- Divide and conquer algorithm.
- Greedy algorithm.
- Brute Force algorithm.
- Randomized algorithm.
What is a classification?
A classification is a division or category in a system which divides things into groups or types. The government uses a classification system that includes both race and ethnicity.Which algorithm is best for multiclass classification?
Most of the machine learning you can think of are capable to handle multiclass classification problems, for e.g., Random Forest, Decision Trees, Naive Bayes, SVM, Neural Nets and so on.What is ML classification?
In machine learning and statistics, classification is the problem of identifying to which of a set of categories (sub-populations) a new observation belongs, on the basis of a training set of data containing observations (or instances) whose category membership is known.What is classification analysis?
Classification analysis is the supervised process of assigning items to categories/classes in order improve the accuracy of our analysis.How do you build a classification model?
- Step 1: Load Python packages.
- Step 2: Pre-Process the data.
- Step 3: Subset the data.
- Step 4: Split the data into train and test sets.
- Step 5: Build a Random Forest Classifier.
- Step 6: Predict.
- Step 7: Check the Accuracy of the Model.
- Step 8: Check Feature Importance.
What is clustering and classification?
1. Classification is the process of classifying the data with the help of class labels whereas, in clustering, there are no predefined class labels. Classification is supervised learning, while clustering is unsupervised learning.What are the different types of classifiers?
Different types of classifiers- Perceptron.
- Naive Bayes.
- Decision Tree.
- Logistic Regression.
- K-Nearest Neighbor.
- Artificial Neural Networks/Deep Learning.
- Support Vector Machine.
Which algorithm is used for prediction?
Naive BayesHow do I choose the best model for machine learning?
How to Choose a Machine Learning Model – Some Guidelines- Collect data.
- Check for anomalies, missing data and clean the data.
- Perform statistical analysis and initial visualization.
- Build models.
- Check the accuracy.
- Present the results.
What do you mean by algorithm?
An algorithm is a step by step method of solving a problem. It is commonly used for data processing, calculation and other related computer and mathematical operations. An algorithm is also used to manipulate data in various ways, such as inserting a new data item, searching for a particular item or sorting an item.Which machine learning algorithm is best?
Top 10 Machine Learning Algorithms- Naïve Bayes Classifier Algorithm.
- K Means Clustering Algorithm.
- Support Vector Machine Algorithm.
- Apriori Algorithm.
- Linear Regression.
- Logistic Regression.
- Artificial Neural Networks.
- Random Forests.