What is HDFS architecture in Hadoop?
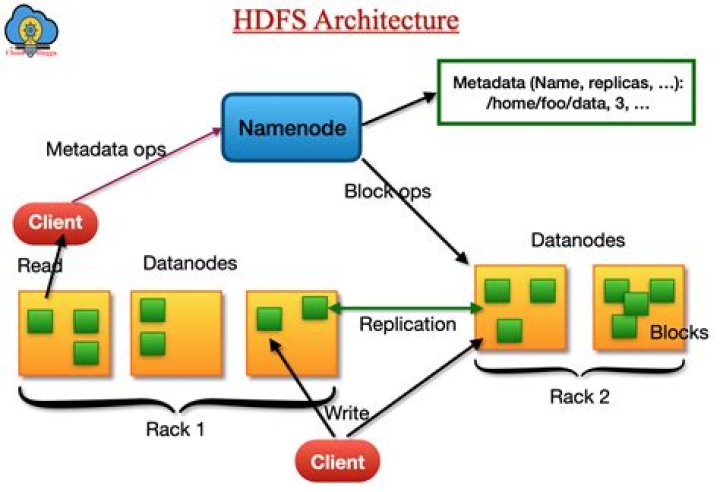
.
Correspondingly, what is the use of HDFS in Hadoop?
HDFS is a distributed file system that handles large data sets running on commodity hardware. It is used to scale a single Apache Hadoop cluster to hundreds (and even thousands) of nodes. HDFS is one of the major components of Apache Hadoop, the others being MapReduce and YARN .
what is DataNode and NameNode in Hadoop? NameNode and DataNode in Hadoop are two components of HDFS. Namenode is the master server. In a non-high availability cluster, there can be only one Namenode. There can be N number of datanode servers that stores and maintains the actual data. Datanodes send block reports to Namenode every 10 seconds.
Regarding this, what is the difference between Hadoop and HDFS?
Hadoop and HBase are both used to store a massive amount of data. But the difference is that in Hadoop Distributed File System (HDFS) data is stored is a distributed manner across different nodes on that network. Whereas, HBase is a database that stores data in the form of columns and rows in a Table.
What is HDFS block in Hadoop?
Hadoop HDFS split large files into small chunks known as Blocks. Block is the physical representation of data. It contains a minimum amount of data that can be read or write. HDFS stores each file as blocks. HDFS client doesn't have any control on the block like block location, Namenode decides all such things.
Related Question AnswersIs Hadoop a database?
Hadoop is not a type of database, but rather a software ecosystem that allows for massively parallel computing. It is an enabler of certain types NoSQL distributed databases (such as HBase), which can allow for data to be spread across thousands of servers with little reduction in performance.What is Hdfs command?
Explore the most essential and frequently used Hadoop HDFS commands to perform file operations on the world's most reliable storage. Hadoop HDFS is a distributed file system that provides redundant storage space for files having huge sizes. It is used for storing files that are in the range of terabytes to petabytes.Where is data stored in Hadoop?
A single NameNode tracks where data is housed in the cluster of servers, known as DataNodes. Data is stored in data blocks on the DataNodes. HDFS replicates those data blocks, usually 128MB in size, and distributes them so they are replicated within multiple nodes across the cluster.How does Hadoop HDFS work?
The way HDFS works is by having a main « NameNode » and multiple « data nodes » on a commodity hardware cluster. Data is then broken down into separate « blocks » that are distributed among the various data nodes for storage. Blocks are also replicated across nodes to reduce the likelihood of failure.What are the components of Hadoop?
It comprises of different components and services ( ingesting, storing, analyzing, and maintaining) inside of it. Most of the services available in the Hadoop ecosystem are to supplement the main four core components of Hadoop which include HDFS, YARN, MapReduce and Common.How does Hadoop work?
How Hadoop Works? Hadoop does distributed processing for huge data sets across the cluster of commodity servers and works on multiple machines simultaneously. To process any data, the client submits data and program to Hadoop. HDFS stores the data while MapReduce process the data and Yarn divide the tasks.Why is Hdfs needed?
As we know HDFS is a file storage and distribution system used to store files in Hadoop environment. It is suitable for the distributed storage and processing. Hadoop provides a command interface to interact with HDFS. The built-in servers of NameNode and DataNode help users to easily check the status of the cluster.How does Hdfs work?
The Hadoop Distributed File System (HDFS) is the primary data storage system used by Hadoop applications. It employs a NameNode and DataNode architecture to implement a distributed file system that provides high-performance access to data across highly scalable Hadoop clusters.Why do we need Hdfs?
1) Ability to store and process huge amounts data: The HDFS layer can store huge volume of data. 2) Computing power- Hadoop's distributed computing model processes data fast.What are the key features of HDFS?
HDFS also makes applications available to parallel processing.- The features of HDFS:
- Fault Tolerance : Since HDFS includes a large number of commodity hardware, failure of components is frequent.
- High Availability: Hadoop HDFS is a highly available file system.
- High Reliability: HDFS provides reliable data storage.


